문자 수식 인식 프로그램
mathpix등 수식에 전문화된 OCR서비스와 다양한 OCR프로그램들이 있는데 성능이 좋은 프로그램은 보통 유료이며 자유롭게 활용하기가 어려운 점들이 있어 Gemini도 출시되고 현재는 무료이지만 앞으로도 저렴한 가격으로 이용 가능 할 거라 예상이 되어 한번 나만의 나만의 문자 수식 인식 프로그램 만들기를 도전해 봅니다.
전문 논문이나 서적들은 수식이 많이 사용되고 텍스트가 인식 안되는 이미지 형식들이 많고 PDF형식의 입력보다 TXT형식 입력이 더 빠르고 정확한 결과를 도출하여 텍스트 인식 프로그램을 만들어보고자 합니다.
구글 Gemini를 이용
코딩은 GPT4를 이용하여 생성
PYTHON
가능성 사전 테스트
이미지를 텍스트와 latex형식으로 변환이 가능한지 사전에 테스트를 시행 프로토타입으로 만들기 편한 Google AI Studio 사용
https://makersuite.google.com/app/prompts/new_freeform
1. 왼쪽 MY Libary탭에서 Structure Prompt를 선택
2. Instruction Option을 아래와 같이 입력
- enter the image, turn it into a document like the ocr program and Convert the formulas in the image to latex format.
3. Model을 Gemino Pro Vision을 선택
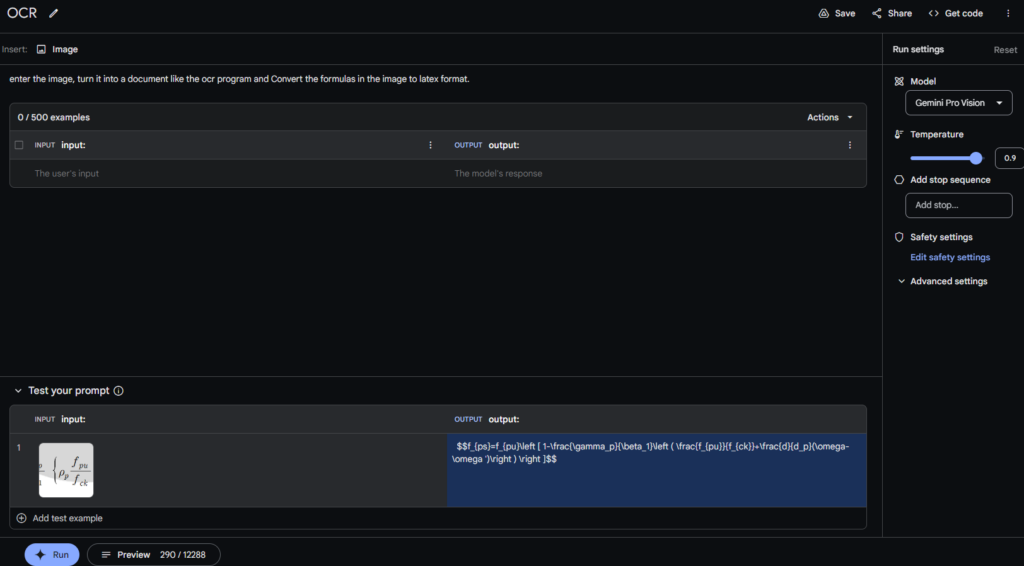
테스트 한 결과 수식이 잘 변환되었는지 확인
output을 MS word에 붙여넣고 수식영역변환을 시켜보고 원래 이미지와 확인해보면 잘 변환이 됩니다.
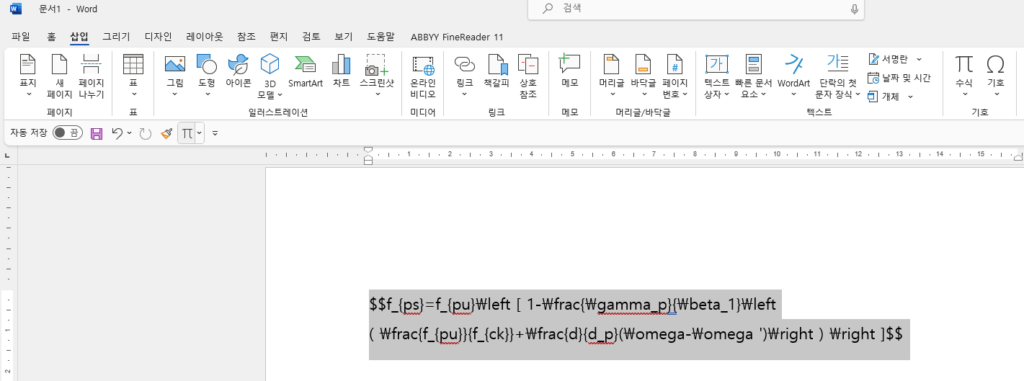
수식부분을 클릭하면
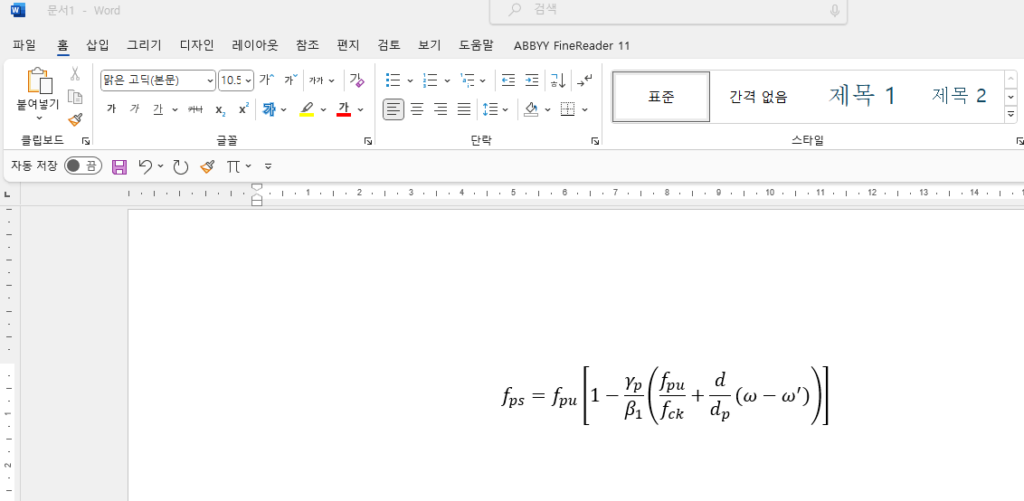
잘 변환이 됩니다.
주의할 점은 이미지 화질이 안 좋으면 변환이 잘 안됩니다. 이런 부분들은 추후 업스케일등 기술을 문자 수식 인식 프로그램에 이용해보려 합니다.
Get code 를 통해 코드 얻기
문자 수식 인식 프로그램 추가 테스트들..
1. 테이블 작성
테이블 형식을 http형식 또는 markdown형식으로 만들어 달라고하는데 gemini에서는 잘 생성되지 않음
gemini에서 텍스트 형식만 만들어논 테이블을 gpt4에서 테이블을 만들어 달라면 깔끔하게 만들어줌 이 부분은 업데이트되면 해결될거라 예상됨
만약 해결되지 않는다면 Gemini작업후 gpt를 한번더 거친다면 좀 더 좋은 결과를 예상(서로의 단점 보완)
2. 복잡한 수식들은 GPT4가 성능이 더 좋음
gemini ultra 업데이트를 기다려봐야 됨.
로컬환경 Python에서 테스트
문자 수식 인식 프로그램 코드는 GPT4를 이용해서 생성했습니다.
import fitz # PyMuPDF
import google.generativeai as genai
import base64
# Configure the API
genai.configure(api_key="your api key")
# Set up the GEMINI model
model = genai.GenerativeModel('gemini-pro-vision')
# : GEMINI API를 이용하여 텍스트로 변환
def convert_image_to_text(image_data):
encoded_image = base64.b64encode(image_data).decode('utf-8')
image_content = {
'mime_type': 'image/jpeg',
'data': encoded_image
}
prompt = "not Describe this pictur just show document like the ocr program and Convert the formulas to latex format."
response = model.generate_content(
contents=[prompt, image_content]
)
return response.text
# Load image from file
with open("C:\\Users\\Administrator\\Documents\\1.jpg", "rb") as image_file:
image_data = image_file.read()
# Convert image to text
text = convert_image_to_text(image_data)결과는 아래처럼 잘 인식되어 나오네요.
Table 9.6.3.1—Cases where Av,min is not required if 0.5Vc < Vu ≤ Vc
Beam type Conditions
Shallow depth h ≤ 250 mm
Integral with slab h ≥ greater of 2.5tf or 0.5bw and
h ≤ 600 mm
Constructed with steel fiber-reinforced normalweight concrete conforming to 26.4.1.5.1(a), 26.4.2(d), and 26.12.5.1(a) and with fc′ ≤ 40 MPa h ≤ 600 mm and
Vu ≤ 0.017√f′c bd
One-way joist system In accordance with 9.8pip install google-generativeai
PDF로 텍스트 및 수식 Latex형식으로 변환
문자 수식 인식 프로그램에 수식들은 Latex형식으로 변환하여 작성하도록 하였습니다.
import fitz # PyMuPDF
import google.generativeai as genai
from docx import Document
import base64
# Configure the API
genai.configure(api_key="your api key")
# Set up the model
generation_config = {
"temperature": 0.5,
"top_p": 1,
"top_k": 32,
"max_output_tokens": 4096,
}
# Set up the GEMINI model
model = genai.GenerativeModel('gemini-pro-vision', generation_config=generation_config)
# 함수 1: GEMINI API를 이용하여 텍스트로 변환
def convert_image_to_text(image_data):
encoded_image = base64.b64encode(image_data).decode('utf-8')
image_content = {
'mime_type': 'image/jpeg',
'data': encoded_image
}
prompt = "not Describe this pictur just show document like the ocr program and Convert the formulas to latex format. and must make a table in Markdown format"
response = model.generate_content(
contents=[prompt, image_content]
)
return response.text
# 함수 2: PDF를 JPG로 변환
def convert_pdf_to_jpg(pdf_path):
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc.load_page(page_num)
pix = page.get_pixmap()
img_data = pix.tobytes("jpg")
images.append(img_data)
doc.close()
return images
# 함수 3: 변환된 텍스트를 Word 파일로 저장
def save_text_to_word(text_list, word_path):
doc = Document()
for text in text_list:
doc.add_paragraph(text)
doc.save(word_path)
# Main Program
pdf_path = "C:\\Users\\Administrator\\Documents\\RCS_Report.pdf"
word_path = "output.docx"
# PDF를 JPG 이미지로 변환
jpg_images = convert_pdf_to_jpg(pdf_path)
# 각 이미지를 텍스트로 변환
texts = [convert_image_to_text(img) for img in jpg_images]
# 변환된 텍스트를 Word 파일로 저장
save_text_to_word(texts, word_path)다른포스팅