설치하기
# Install the ultralytics package using pip
이번에는 YOLOv8 설치 와 실행을 해보겠습니다. 저는 vscode를 사용하고 있고 아래 명령어를 치면 설치가 됩니다. 파이썬 기초지식만 있으면 10분이면 따라 하실 수 있을 정도로 간단합니다.
pip install ultralytics먼저 시작하기전 이전 YOLOv8소개글 과
YOLOv8공식 홈페이지에 방문하여, 관련 내용을 보는 것을 추천 드려요.
YOLOv8 설치하여 이미지 인식 실행
코드
YOLOv8 설치 와 실행하기 위해서 여러분이 가지고 있는 파일을 이용해서 인식 시켜보려면 아래 코드를 사용해봅시다. 하지만 공식 홈페이지에 안내하는 코드를 그대로 실행 시키면 오류가 납니다.
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
# Run batched inference on a list of images
results = model(['im1.jpg', 'im2.jpg']) # return a list of Results objects
# Process results list
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Class probabilities for classification outputs왜냐하면 im1.jpg와 im2.jpg파일 경로와 이미지 이름을 수정해야 하는데요 저는 코딩을 잘 모르니 냅다 GPT에게 물어봅니다.
- 질문 :

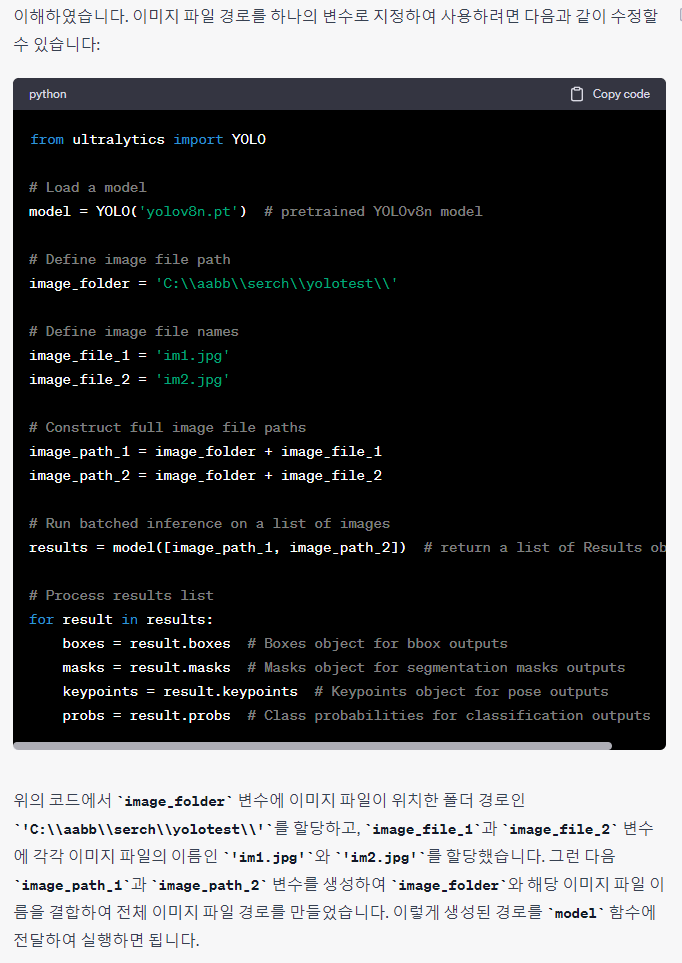
수정한 코드를 입력해봅니다.
아래 코드에서 Image folder는 이미지 파일이 있는 경로 그리고 file1,2는 이미지파일 이름입니다.
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
# Define image file path
image_folder = 'C:\\aabb\\serch\\yolotest\\'
# Define image file names
image_file_1 = 'im1.jpg'
image_file_2 = 'im2.jpg'
# Construct full image file paths
image_path_1 = image_folder + image_file_1
image_path_2 = image_folder + image_file_2
# Run batched inference on a list of images
results = model([image_path_1, image_path_2]) # return a list of Results objects
# Process results list
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Class probabilities for classification outputs
실행

pretained모델 yolov8n.pt파일을 불러오는데 여기서 이 용어는
“pretrained”는 미리 학습된 모델을 의미합니다. 딥 러닝 모델은 대량의 데이터셋에서 학습하여 일반적인 이미지 인식, 객체 감지, 자연어 처리 등의 작업을 수행할 수 있도록 학습됩니다. 하지만 이러한 모델을 처음부터 학습 시키는 데에는 많은 시간과 계산 리소스가 필요합니다.
따라서, pretrained 모델은 이미 대규모 데이터셋에서 사전에 학습되어 일반적인 패턴과 특징을 학습한 모델을 의미합니다. 이러한 모델을 사용하면 처음부터 학습시키는 대신, 이전에 학습된 모델을 기반으로 새로운 작업에 대한 예측을 수행할 수 있습니다.
pretrained 모델은 일반적으로 이미지넷(ImageNet)과 같은 대형 데이터셋에서 사전 학습된 모델을 의미합니다. 이 모델들은 이미지 분류, 객체 감지, 세그멘테이션 등 다양한 컴퓨터 비전 작업에 사용될 수 있습니다. pretrained 모델을 사용하면 소규모 데이터셋에서도 좋은 성능을 얻을 수 있고, 학습 시간과 비용을 절약할 수 있습니다.
이런 뜻을 가지고 있습니다.
프로그램 실행 결과

제가 넣은 그림은 위에 그림을 넣었는데 이렇게 잘 실행이 되었습니다.
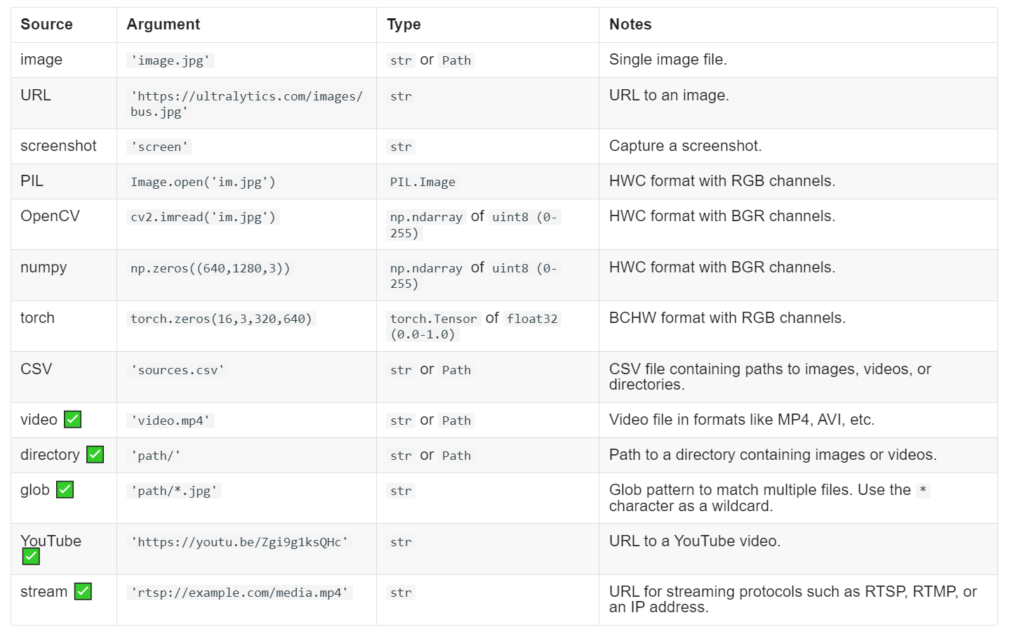
참고로 이미지 입력 방법은 아래와 같은 형식들을 지원해 주기 때문에 사용자가 편리하게 이용할 수 있습니다.
박스형상 으로 확인
텍스트로만 보면 인식을 하긴 했는데 어디를 인식 한지 확인하기가 힘든데요. 이럴 때 편리한 기능이 기존 사진에 인식한 내용과 위치를 박스로 표기할 수 있습니다. 어렵지 않고 다음을 따라하시면 됩니다.
공식 홈페이지에 코드를 따라하시면 창이 실행되고 바로 꺼지는 문제가 생기는데 꺼지지 않도록 코드를 추가해주면 됩니다.
from ultralytics import YOLO
import cv2
# Load a model
model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
model.predict(source="0", show=True, stream=True, classes=0) # [0, 3, 5] for multiple classes
# Define image file path
image_folder = 'C:\\aabb\\serch\\yolotest\\'
# Define image file names
image_file_1 = 'im1.jpg'
image_file_2 = 'im2.jpg'
# Construct full image file paths
image_path_1 = image_folder + image_file_1
image_path_2 = image_folder + image_file_2
# Run batched inference on a list of images
results = model([image_path_1, image_path_2]) # return a list of Results objects
model.predict(source="0", show=True, stream=True, classes=0)
# Process results list
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Class probabilities for classification outputs
# Print box coordinates
print("Box coordinates:")
for box in boxes:
print(box)
# Display result with boxes
result.plot()
cv2.waitKey(0)
cv2.destroyAllWindows()
이렇게 실행하면
아래와 같이 결과가 나옵니다.

아주 작은 용량의 학습된 모델로 적용했음에도 불구하고 버스 부분이 좀 곂치긴 하지만 사진 오른쪽 오토바이까지 인식한 점을 보면 정확도가 엄청납니다. 모델은 좀 더 학습 시킨다면 엄청난 정확도가 예상되네요.
결론
이번 YOLOv8 설치 와 실행 포스팅을 하면서 이미지 인식 뿐만 아니라 실시간 영상으로도 놀라운 정확도로 사물을 인식하는 기술을 비전공자이며, 코딩을 따로 배워본적 없는 저도 이렇게 쉽게 따라 할 수 있도록 개발되어 있어 신기합니다.
YOLOv8 설치 와 실행에 관심이 있는 분들은 위에 내용을 그대로 복사 붙여 넣어 따라해 보시면 좋을 것 같아요. 앞으로는 YOLOV8을 접목해서 적용할 분야에 대한 고민을 해보려고 합니다. 또한, 추후 실시간 영상으로 사물 인식을 적용 해보고 싶네요
안녕하세요 따라해보고 있었는데, 계속 파일 또는 디렉토리를 찾지 못한다고 뜨는데 해결방법 좀요
디렉토리는 제가 실행한 경로이고 해당파일 실행시에는 본인 컴퓨터에 있는 경로에 설정해주셔야되요
파일 경로명을 올바르게 한 것 같은데 계속 파일을 찾지 못하네요 ㅜㅜ