https://github.com/ultralytics/ultralytics/issues/1496
https://github.com/ultralytics/ultralytics/issues/980
https://github.com/ultralytics/ultralytics/issues/3066
https://github.com/ultralytics/ultralytics/issues/2375
http://karpathy.github.io/2019/04/25/recipe/
https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results/#training-settings
https://blog.roboflow.com/detect-small-objects/
YOLOv8 학습 결과 분석
YOLOv8 학습 결과를 분석하는 것은 모델의 성능을 평가하고 개선하기 위해 매우 중요합니다. 검증된 모델은 믿을 수 있는 모델입니다. 학습 결과 분석을 통해 모델의 성능을 입증하고 신뢰성을 확보할 수 있습니다. 이를 통해 물체 검출 작업의 품질과 모델의 성능을 높일 수 있습니다.
아래는 YOLOv8 학습 결과를 분석하는 지표에 대한 간략한 설명입니다.
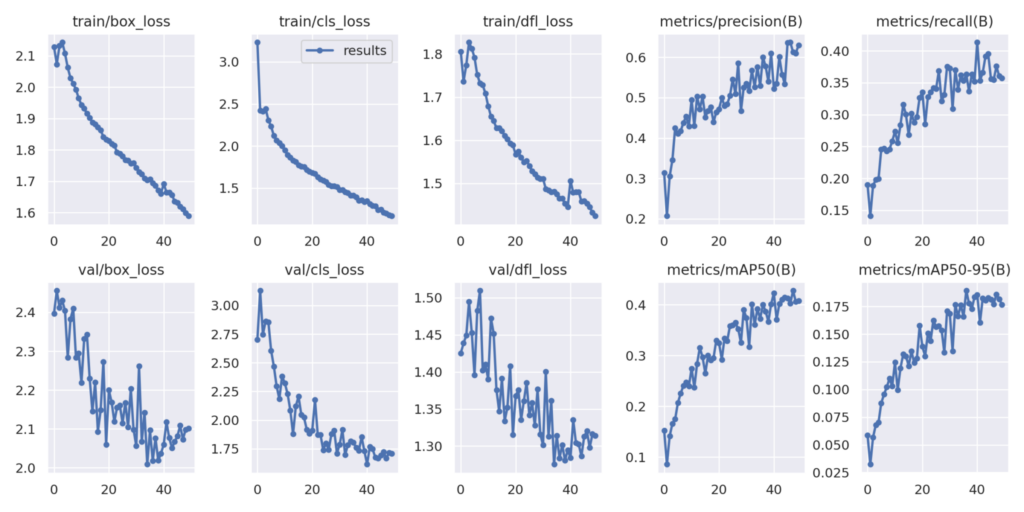
YOLOv8 학습 지표
train/box_loss
train/box_loss는 YOLO (You Only Look Once)와 같은 객체 탐지 모델에서 사용되는 학습 지표 중 하나입니다. 이 지표는 실제 bounding box와 모델이 예측한 bounding box 사이의 차이를 측정합니다.
Box loss는 일반적으로 IoU (Intersection over Union) 또는 다른 유사한 메트릭을 사용하여 계산됩니다. 목표는 이 box_loss 값을 최소화하는 것이며, 이렇게 하면 모델이 더 정확한 bounding box 예측을 할 수 있습니다.
이 지표는 모델이 객체의 위치를 얼마나 잘 예측하는지에 대한 정보를 제공하므로, 이 값을 최소화하면 객체 탐지 성능이 향상됩니다.
train/cls_loss
train/cls_loss (Classification Loss)는 객체 탐지 모델에서 사용되는 또 다른 학습 지표입니다. 이 지표는 모델이 예측한 클래스 라벨과 실제 클래스 라벨 사이의 차이를 측정합니다.
일반적으로 이 loss는 cross-entropy loss 함수를 사용하여 계산됩니다. 목표는 cls_loss 값을 최소화하여, 모델이 객체의 클래스를 더 정확하게 분류할 수 있도록 하는 것입니다.
이 지표는 모델이 어떤 객체가 어떤 클래스에 속하는지를 얼마나 잘 분류하는지에 대한 정보를 제공합니다. 따라서 이 값을 최소화하면 객체 탐지의 성능이 전반적으로 향상됩니다.
train/dfl_loss
train/dfl_loss (Distance-based Feature Learning Loss)는 주로 Anchor-Free 객체 탐지 모델에서 사용되는 지표입니다. 이 지표는 모델이 예측한 특성과 실제 특성 사이의 거리를 측정합니다. DFL loss는 모델이 더 정확한 특성을 학습할 수 있도록 도와줍니다.
DFL loss는 일반적으로 Euclidean 거리나 Cosine 유사도와 같은 거리 메트릭을 사용하여 계산될 수 있습니다. 목표는 이 dfl_loss 값을 최소화하는 것이며, 이렇게 하면 모델이 더 정확한 특성을 학습할 수 있습니다.
이 지표는 객체의 특성을 얼마나 잘 학습하는지에 대한 정보를 제공하므로, 값이 낮을수록 객체 탐지 성능이 향상될 가능성이 높습니다.
metrics/precision
metrics/precision은 모델의 성능을 평가하는 지표 중 하나로, 주로 분류나 객체 탐지 문제에서 사용됩니다. Precision은 True Positive (TP)와 False Positive (FP)을 이용해 계산됩니다. 공식은 다음과 같습니다:

- True Positive (TP): 모델이 Positive 클래스로 예측하고, 실제로도 Positive 클래스인 경우
- False Positive (FP): 모델이 Positive 클래스로 예측했지만, 실제로는 Negative 클래스인 경우
Precision 값이 높을수록 모델이 Positive 클래스를 예측하는 데 있어 더 정확하다는 것을 의미합니다. 하지만 이 값이 높다고 해서 모델의 전반적인 성능이 높다고 판단할 수는 없으며, 다른 지표들과 함께 종합적으로 평가해야 합니다.
metrics/recall
metrics/recall은 모델의 성능을 평가하는 또 다른 중요한 지표입니다. 주로 분류나 객체 탐지 문제에서 사용됩니다. Recall은 True Positive (TP)와 False Negative (FN)을 이용하여 계산됩니다. 공식은 다음과 같습니다:

- True Positive (TP): 모델이 Positive 클래스로 예측하고, 실제로도 Positive 클래스인 경우
- False Negative (FN): 모델이 Negative 클래스로 예측했지만, 실제로는 Positive 클래스인 경우
Recall 값이 높을수록 모델이 Positive 클래스의 실제 인스턴스를 더 많이 찾아낼 수 있다는 것을 의미합니다. 그러나 이 지표만 높다고 해서 모델이 전반적으로 좋다고 판단할 수는 없으며, Precision과 함께 종합적으로 모델을 평가해야 합니다.
val/box_loss
val/box_loss는 검증 데이터셋(validation dataset)에서의 box loss를 나타냅니다. 학습 데이터셋에서의 train/box_loss와 같은 방식으로 계산되지만, 이 값은 모델이 새로운, 학습에 사용되지 않은 데이터에 대해 얼마나 잘 동작하는지 평가하는 데 사용됩니다.
검증 데이터셋에서의 val/box_loss가 낮으면 모델이 일반화되었다고 볼 수 있습니다. 그러나 이 값이 너무 낮으면 모델이 과적합(overfitting)된 것일 가능성이 있으므로 주의가 필요합니다.
val/box_loss는 모델 학습 중간 중간 계산되어, 이를 통해 학습의 진행 상황을 모니터링하고 필요한 경우 하이퍼파라미터를 조정할 수 있습니다.
val/cls_loss
val/cls_loss (Validation Classification Loss)는 검증 데이터셋에 대한 분류 손실을 나타냅니다. 이 지표는 모델이 학습 데이터셋에 대해서만 잘 동작하는지, 아니면 새로운 데이터에 대해서도 잘 일반화되는지를 평가하는 데 사용됩니다.
val/cls_loss는 일반적으로 cross-entropy loss 같은 메트릭을 사용하여 계산되며, 값이 낮을수록 모델이 검증 데이터셋에 대해 더 잘 일반화되고 있다는 것을 의미합니다.
이 지표가 높으면 모델이 과적합(overfitting)되었을 가능성이 있으므로, 학습 과정을 조정할 필요가 있을 수 있습니다. val/cls_loss는 주기적으로 측정되어 모델의 성능을 모니터링하는 데 사용됩니다.
val/dfl_loss
val/dfl_loss (Validation Distance-based Feature Learning Loss)는 검증 데이터셋에 대한 DFL 손실을 나타냅니다. 이 지표는 모델이 학습 데이터셋에서 잘 동작하는지, 그리고 새로운 데이터에 대해 얼마나 잘 일반화되는지를 평가하는 데 사용됩니다.
검증 데이터셋에서의 val/dfl_loss가 낮을 경우, 모델이 일반적으로 잘 일반화되고 있다고 볼 수 있습니다. 그러나 이 값이 지나치게 낮으면 모델이 과적합(overfitting)되었을 가능성이 있으므로 주의가 필요합니다.
이 지표는 주기적으로 모델의 성능을 모니터링하는 데 사용되며, 필요한 경우 학습 과정을 조정하는 데 도움을 줍니다.
metrics/mAP50
metrics/mAP50는 “Mean Average Precision at IoU=0.5″를 의미합니다. 이는 객체 탐지 모델의 성능을 평가할 때 널리 사용되는 지표입니다. IoU (Intersection over Union)가 0.5 이상인 경우만을 고려하여 평균 정밀도(mAP)를 계산한 것입니다.
- Mean Average Precision (mAP): 모든 클래스에 대한 평균 정밀도를 의미합니다.
- IoU (Intersection over Union): 예측한 바운딩 박스와 실제 바운딩 박스의 겹치는 영역을 측정하는 지표입니다.
mAP50 값이 높을수록 모델이 더 정확한 객체 탐지 성능을 보이고 있다고 판단할 수 있습니다. 이 지표는 모델의 전반적인 성능을 이해하는 데 유용합니다.
metrics/mAP50-95
metrics/mAP50-95는 “Mean Average Precision at IoU ranging from 0.5 to 0.95″를 의미합니다. 이는 객체 탐지 모델의 성능을 평가하는 데 사용되는 종합적인 지표입니다. 여기서 IoU (Intersection over Union) 값이 0.5에서 0.95까지 다양한 임계값에 대한 평균 정밀도(mAP)를 계산합니다.
이 지표는 모델이 다양한 IoU 임계값에서 얼마나 잘 동작하는지를 종합적으로 평가할 수 있습니다. mAP50-95 값이 높을수록 모델이 더 정확하고 다양한 상황에서도 잘 동작한다고 볼 수 있습니다.
일반적으로 mAP50-95는 객체 탐지 모델의 성능을 광범위하게 평가하는 데 가장 많이 사용되는 지표 중 하나입니다.
위의 지표 들로 원하는 커스텀 YOLOv8 학습 결과를 분석하고 성능을 평가하고 개선 할 수 있습니다.
Yolo 학습 단계
YOLOv8 학습단계
- 데이터셋 준비: 작은 물체를 검출하려는 이미지를 데이터셋에 포함시킵니다. 이미지에는 물체의 경계 상자 주석이 달려있어야 합니다.
- 필요한 종속성 설치: 필요한 종속성을 설치합니다. 이는 YOLOv8와 관련된 종속성(PyTorch 등)을 포함합니다.
- YOLOv8 모델 설정: YOLOv8 모델 구성 파일을 데이터셋과 원하는 훈련 매개변수에 맞게 설정합니다. 필요에 따라 모델 아키텍처와 하이퍼파라미터를 조정합니다.
- 모델 훈련: 준비한 데이터셋을 사용하여 훈련을 시작합니다. 훈련 진행 상황을 모니터링하여 수렴하고 만족스러운 결과를 얻습니다.
- 모델 평가: 훈련 후 모델의 성능을 별도의 검증 또는 테스트 세트에서 평가합니다. 정밀도, 재현율, F1 점수 등과 같은 메트릭을 측정하여 작은 물체 검출의 정확성을 평가합니다.
- 세부 튜닝 및 반복: 결과가 만족스럽지 않은 경우 하이퍼파라미터를 조정하거나 훈련 데이터셋의 크기를 늘리거나 데이터 증강 기법을 적용하여 모델을 세부적으로 튜닝할 수 있습니다. 원하는 성능을 얻을 때까지 훈련 과정을 반복합니다.
작은 물체 감지
YOLOv8 학습을 통해 작은 물체를 검출하는 모델을 훈련하는 것은 때로는 어려울 수 있습니다. 결과를 개선하기 위해 몇 가지 제안을 해보겠습니다:
- 물체 크기 증가: 훈련 이미지의 크기를 조정하여 관심 대상인 열쇠와 같은 물체가 이미지의 큰 부분을 차지하도록 만듭니다. 이렇게 하면 모델이 주요한 세부 정보를 더 잘 포착할 수 있습니다.
- 데이터셋 증강: 무작위 크롭, 회전, 뒤집기와 같은 증강 기법을 사용하여 훈련 데이터의 다양성과 복잡성을 높일 수 있습니다. 이러한 증강은 모델의 일반화 능력을 향상시키고 작은 물체를 효과적으로 검출할 수 있게 해줍니다.
- 모델 아키텍처 조정: YOLOv8 아키텍처를 수정하여 작은 물체를 더 잘 처리할 수 있도록 고려해볼 수 있습니다. 네트워크에서 다운샘플링 스트라이드를 줄이거나 더 세부적인 세부 정보를 포착하기 위해 추가적인 레이어를 추가해볼 수 있습니다.
- 훈련 반복 횟수 증가: 때로는 모델이 수렴하고 작은 물체를 검출하는 세부사항을 학습하기 위해 더 많은 훈련 반복이 필요할 수 있습니다. 훈련 반복 횟수를 늘려보고 과정 중에 모델의 성능을 모니터링하는 것이 좋습니다.
모델의 성능을 평가할 때 정밀도, 재현율 및 평균 평균 정밀도(mAP)와 같은 검증 메트릭을 평가하는 것을 잊지 마세요. 이러한 메트릭은 모델의 성능을 객관적으로 평가하고 추가 개선 영역을 식별하는 데 도움이 될 것입니다.
인식하지 말아야 할 이미지를 함께 훈련
YOLOv8 학습에서 객체를 인식해야 할 이미지와 인식하지 말아야 할 이미지를 함께 훈련에 사용하려면, 일반적으로 두 가지 방법이 있습니다:
- Negative Samples: 인식하지 말아야 하는 이미지는 객체가 없는 “Negative Sample”로 표시됩니다. 이러한 샘플에는 어떠한 라벨도 붙여져 있지 않습니다. 따라서, 학습 도중 이러한 이미지에서는 객체를 발견하지 않아야 합니다.
- Background Class: 인식하지 않아야 할 객체에 대해서는 “Background” 등의 특별한 클래스 라벨을 부여할 수 있습니다. 이 방법은 주로 물체 검출이 아닌 분류 문제에서 사용됩니다.
이 두 가지 방법을 데이터셋 생성 단계에서 적절히 섞어 사용하면, 모델은 객체를 인식해야 할 때와 인식하지 말아야 할 때를 구분할 수 있게 됩니다.